Reaction Bench: Lesson 1
![]()
Part 1:
In this lesson, I will be taking you through how our reaction bench environment works and how an RL agent might interact with the environment.
The reaction bench environment is meant to as it sounds simulate a reaction, in most reaction benches the agent will have a number of reagents and the ability to play with the environmental conditions of the reaction and through doing this the agent is trying to maximize the yield of a certain desired material. For the reaction bench we use a reaction file which specifies the mechanics of a certain reaction or multiple reactions. For instance the Wurtz reaction is made up of 6 different reactions and as such is a very complicated reaction which the agent has to try and learn the mechanisms of the reaction environment it is in. For this lesson we will be using a simplified version of the wurtz reaction to introduce you to how actions affect the environment.
Below is just some simple code that loads our desired environment
import gymnasium as gym
import chemistrylab
import matplotlib,time
import numpy as np
from matplotlib import pyplot as plt
from chemistrylab.util import Visualization
from IPython.display import display,clear_output
Visualization.use_mpl_light(size=2)
# IF you are using dark mode
First let’s load up the environment, I highly recommend you look at the source code for the reaction bench and reaction, it should help provide insight into how this all works. Further the lesson on creating a custom reaction environment will also help give insight into the reaction mechanics.
If you run the cell below you will see a graph appear that looks something like this:
env = gym.make('GenWurtzReact-v2')
env.reset()
env.step([1,1,1,1,1])
rgb = env.render()
plt.imshow(rgb)
plt.axis("off")
plt.show()
_ = env.reset()
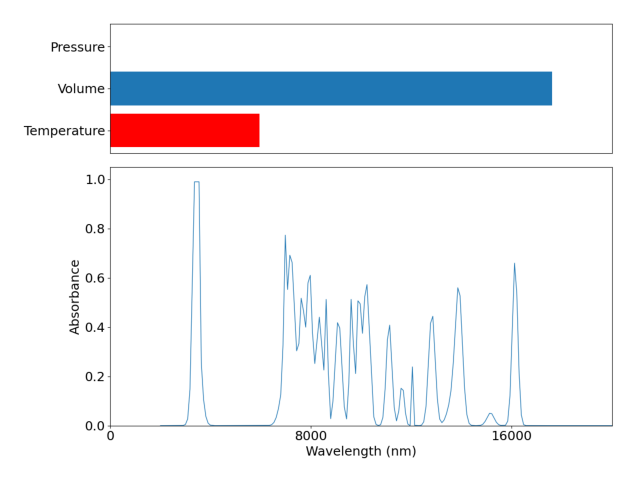
Understanding the graph above is important to understanding how the agent will have to understand the environment. On the left we can see the absorbance spectra of the materials in our reaction vessel, and on the right we have a relative scale of a number of important metrics. From left to right we have time passed, temperature, volume (solvent) , presure, and the quantity of reagents that we have available to use. All of this data is what the RL agent has inorder for it to try and optimize the reaction pathway.
The reaction we are using is as follows:
 2 1-chlorohexane + 2 Na –> dodecane + 2 NaCl
2 1-chlorohexane + 2 Na –> dodecane + 2 NaCl
This reaction is performed in an aqueous state with diethylether as the solvent.
With all that out of the way let’s focus our attention to the action space. For this reaction environemnt our action space is represented by a 6 element vector.
Temperature |
1-chlorohexane |
2-chlorohexane |
3-chlorohexane |
Na |
|
|---|---|---|---|---|---|
Value range: |
0-1 |
0-1 |
0-1 |
0-1 |
0-1 |
As you might have noticed now, the reaction bench environment deals with a continuous action space. So what exactly do these continuous values represent? For the environmental conditions, in this case Volume and Temperature 0 represents a decrease in temperature or volume by dT or dV (specified in the reaction bench), 1/2 represents no change, and 1 represents an increase by dT or dV. For the chemicals, 0 represents adding no amount of that chemical to the reaction vessel, and 1 represents adding all of the originally available chemical (there is a negative reward if you try to add more chemical than is available).
Below you will find a code cell that will allow you to interact with the gym environment, I highly encourage you to play around with different actions and to not the rewards as well.
d = False
state = env.reset()
total_reward = 0
action = np.ones(env.action_space.shape[0])
print(f'Target: {env.target_material}')
for i, a in enumerate(env.actions):
v,event = env.shelf[a[0][0][0]],a[0][0][1]
action[i] = float(input(f'{v}: {event.name} -> {event.other_vessel}| '))
while not d:
action = np.clip(action,0,1)
o, r, d, *_ = env.step(action)
total_reward += r
time.sleep(0.1)
clear_output(wait=True)
print(f'reward: {r}')
print(f'total_reward: {total_reward}')
rgb = env.render()
plt.imshow(rgb)
plt.axis("off")
plt.show()
Part 2:
Here I will provide instructions on how to maximize the return of this reaction environment.
This is fairly simple for this task and have thus provided some script which demonstrates our strategy, and I encourage you to try your own strategy and see how it performs. In this case cour strategy is to maximize the temperature and add in all our reagents. For example, to make dodecane we want to add 1-chlorohexane and Na. This gives us an action vector of:
Temperature |
1-chlorohexane |
2-chlorohexane |
3-chlorohexane |
Na |
|---|---|---|---|---|
1 |
1 |
0 |
0 |
1 |

To see this in action run the following code cell:
def predict(observation):
t = np.argmax(observation[-7:])
#targs = {0: "dodecane", 1: "5-methylundecane", 2: "4-ethyldecane", 3: "5,6-dimethyldecane", 4: "4-ethyl-5-methylnonane", 5: "4,5-diethyloctane", 6: "NaCl"}
actions=np.array([
[1,1,0,0,1],#dodecane
[1,1,1,0,1],#5-methylundecane
[1,1,0,1,1],#4-ethyldecane
[1,0,1,0,1],#5,6-dimethyldecane
[1,0,1,1,1],#4-ethyl-5-methylnonane
[1,0,0,1,1],#4,5-diethyloctane
[1,1,1,1,1],#NaCl
],dtype=np.float32)
return actions[t]
d=False
o,*_=env.reset()
total_reward=0
while not d:
action = predict(o)
o, r, d, *_ = env.step(action)
total_reward += r
time.sleep(0.1)
clear_output(wait=True)
print(f"Target: {env.target_material}")
print(f"Action: {action}")
print(f'reward: {r}')
print(f'total_reward: {total_reward}')
rgb = env.render()
plt.imshow(rgb)
plt.axis("off")
plt.show()
Now we’re done! I hope you have a better sense of how the reaction environment works and the process through which an RL agent must go through to learn the environment.